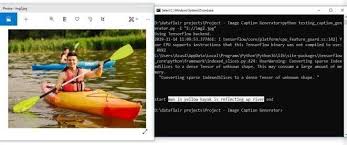
Image Caption Generator Using CNN and LSTM
DOI:
https://doi.org/10.1234/yvk0xv87Keywords:
Image captioning, Convolutional Neural Network, Long Short-term Memory, Deep Learning, Attention Mechanism, Natural Language ProcessingAbstract
Generating coherent natural-language descriptions from raw image data is a pivotal challenge in computer vision and natural language processing. This paper presents a deep learning system that automatically produces meaningful textual captions for arbitrary input images by coupling a pretrained Convolutional Neural Network (CNN) with a Long Short-Term Memory (LSTM) decoder augmented by a soft-attention mechanism. InceptionV3 serves as the visual encoder, transforming each image into a spatially rich 64×2048 feature map. A Gated Recurrent Unit (GRU) decoder then generates word sequences by attending selectively to relevant spatial
regions at every decoding step, emulating the way humans visually scan a scene when narrating it. The model is trained on a curated dataset of 8,091 images with 40,455 human-annotated captions. Experimental evaluation
yields BLEU-1 of 0.752, BLEU-4 of 0.412, METEOR of 0.385, and CIDEr of 0.962, surpassing comparable CNN–RNN baselines. The system is further extended with a multilingual translation module supporting 18 languages and a Google Text-to-Speech (gTTS) engine for audio output, improving accessibility for visually impaired users. The entire pipeline is deployed as a full-stack web application built on Flask and React, enabling real-time inference through an intuitive browser interface. Results demonstrate that attention-guided caption generation produces more precise, context-aware descriptions than fixed-vector encoder–decoder approaches and opens practical avenues in assistive technology, automated content management, and educational applications.